Материалы по тегу: biren technology
|
02.01.2026 [22:40], Владимир Мироненко
«Маленький китайский дракон» Biren привлёк $717 млн в ходе IPOКитайский производитель ускорителей Shanghai Biren Intelligent Technology провёл в последний день 2025 года первичное публичное размещение акций (IPO) на гонконгской фондовой бирже, в результате которого привлёк сумму в эквиваленте $717 млн. Всего было продано 284,8 млн акций по $19,6 за единицу, что является верхней границей ценового диапазона, запрошенного Biren, сообщил ресурс SiliconANGLE. По данным ресурса, спрос на акции Biren среди институциональных инвесторов почти в 26 раз превысил предложение. Biren стала третьим китайским поставщиком видеокарт, вышедшим на биржу в декабре. До этого на бирже начали торги MetaX и Moore Threads, чьи акции в первые дни торгов взлетели в цене на 400 и 700 % соответственно. Это говорит о том, что акции Biren также могут вырасти в цене после начала торгов в пятницу. Biren, Enflame, MetaX и Moore Threads входит в число т.н. китайских «четырёх маленьких драконов» в сегменте GPU и ИИ-ускорителей. В документации для IPO компания Biren сообщила, что в 2024 году её выручка составила ¥336,8 млн (около $47,8 млн), прибыли пока нет. Объём незавершенных и заключённых контрактов составляет около $300 млн. Компания была основана в 2019 году, а три года спустя представила серверный ИИ-ускоритель BR100 на базе собственной архитектуры Bi Liren, изготовленный с использованием 7-нм техпроцесса TSMC и технологии упаковки CoWoS. По оценкам самой Biren, производительность BR100 сопоставима с NVIDIA A100. 
Источник изображения: Biren Technology Также стало известно, что вскоре последует IPO китайской полупроводниковой компании. Производитель микросхем памяти CXMT объявил во вторник о планах продать 10,6 млрд акций на сумму $4,22 млрд. Вырученные от IPO средства компания планирует направить на финансирование исследовательских проектов в области DRAM и модернизации своих производственных линий. CXMT также строит завод по производству памяти HBM, который планирует запустить к концу 2026 года.
24.12.2025 [00:42], Владимир Мироненко
Biren, один из «четырёх маленьких драконов», планирует привлечь $624 млн благодаря IPO в ГонконгеШанхайский разработчик ИИ-ускорителей Biren Technology начал формирование книги заявок для своего первичного публичного размещения акций (IPO) в Гонконге, которое пройдёт 2 января, сообщил ресурс South China Morning Post. Компания выставит на продажу 247,7 млн акций по цене от HK$17 до HK$19,60 за акцию, планируя привлечь до HK$4,85 млрд ($624 млн). Biren входит в число китайских «четырёх маленьких драконов» в сегменте GPU — наряду с материковыми Moore Threads Technology, MetaX Integrated Circuits и Enflame Technology. Для участия в IPO компания привлекла 23 ключевых инвестора, включая крупные компании по управлению активами, отечественные паевые инвестиционные фонды и страховые компании, международные долгосрочные фонды и хедж-фонды, которые согласились инвестировать $372,5 млн в акции и держать их в течение шести месяцев. Qiming Venture Partners, Ping An Group, Lion Global Investors, азиатский хедж-фонд York Capital Management, MY.Alpha Management HK Advisors, подразделение по управлению активами Prudential Eastspring, UBS, Digital China и China Southern Asset Management. 
Источник изображения: Dan Freeman/unsplash.com Biren станет первым разработчиком GPU из материкового Китая, вышедшим на биржу в Гонконге. Он присоединится к растущему числу китайских технологических компаний с материка, стремящихся к листингу в Гонконге, в числе которых ИИ-стартап MiniMax, который успешно прошёл слушания по IPO на Гонконгской фондовой бирже в воскресенье, и ИИ-стартап Knowledge Atlas Technology (Zhipu AI), прошедший эту процедуру в минувшую пятницу. IPO Biren проходит на фоне стремительного дебюта её конкурентов Moore Threads Technology и MetaX Integrated Circuits в этом месяце на фондовой бирже в Шанхае, где их акции подскочили на 425 и 693 % соответственно. Biren начала получать доход от своих ИИ-решений в 2023 году. По данным South China Morning Post, в прошлом году её выручка составила ¥336,8 млн ($47,9 млн), а в I полугодии 2025 года — ¥58,9 млн ($8,4 млн). Несмотря на рост доходов, Biren остается убыточной, поскольку активно инвестирует в исследования и разработки. Компания сообщила, что большую часть средств, полученных от IPO, направит на R&D, а также на коммерциализацию своих решений. Развитие компании притормозили санкции США — Biren лишили доступа к мощностям TSMC. Аналитики рассматривают проведение IPO Biren как ключевую проверку международного доверия к китайским компаниям, занимающимся выпуском аппаратным обеспечением для ИИ-нагрузок. Агентство Bloomberg привело слова руководителя Barclays Мэтта Томса (Matt Toms): «Китай очень быстро догоняет в войне за чипы. Меня бы не удивило, если бы в 2026 или 2027 году мы стали свидетелями “момента DeepSeek” для чипов, когда Китай начнёт производить недорогие конкурентоспособные чипы».
09.11.2022 [14:50], Владимир Мироненко
Производители специально ухудшают характеристики чипов для китайских серверов, чтобы избежать санкций СШАВ связи с вводом Соединёнными Штатами новых экспортных ограничений на поставки в Китай, производители стали намеренно снижать производительность чипов, чтобы соответствовать требованиям экспортного контроля США и избежать проблем с получением специальных лицензий. Как отметил ресурс The Register, у систем, построенных на чипах NVIDIA, изготовленных на производственных мощностях TSMC для поставок в Китай, характеристики хуже по сравнению с теми, что были ранее. В частности, китайский производитель серверов Inspur указал на использование вместо ускорителя NVIDIA A100 чипа A800, разработанного NVIDIA специально для Китая в соответствии с экспортными ограничениями. Китайские производители H3C и Omnisky тоже представили решения на базе A800. Данный ускоритель, по словам NVIDIA, начала производиться в III квартале этого года. У A800 скорость передачи данных составляет 400 Гбайт/с, тогда как у A100 этот показатель равен 600 Гбайт/с, причём обойти эти ограничения, по словам NVIDIA, невозможно. Речь, судя по всему, идёт о характеристиках интерконнекта NVLink, которые прямо влияют на производительность кластеров из двух и более ускорителей в машинном обучении и других задачах. Изменения касаются 40- и 80-Гбайт вариантов с интерфейсами PCIe и SXM. 
Источник изображения: Inspur Между тем ускорители, находящиеся в разработке и выпускаемые TSMC по контракту с Alibaba и стартапом Biren Technology, тоже, как сообщается, имеют пониженную скорость передачи данных. Это позволит выпускать данные чипы на заводе TSMC, не опасаясь санкций США. До этого TSMC приостановила выпуск 7-нм чипов ускорителей Biren BR100 как раз из-за возможных санкций со стороны Вашингтона.
22.08.2022 [20:55], Алексей Степин
Китайский ускоритель Birentech BR100 готов бросить вызов NVIDIA A100Как известно, Китай первым в мире успешно ввёл в эксплуатацию суперкомпьютеры экзафлопсного класса, но современная HPC-система практически немыслима без ускорителей. Однако и здесь китайские разработчики подготовили прорыв: на конференции Hot Chips 34 компания Birentech рассказала о чипе BR100, решении, которое может бросить вызов как AMD, так и NVIDIA. Новинка базируется на архитектуре собственной разработки под кодовым названием Bi Liren. Это первый китайский ускоритель общего назначения, использующий чиплетную компоновку и поддерживающий PCI Express 5.0/CXL. Новые ускорители будут сопровождаться полноценной программной поддержкой, начиная с драйверов и библиотек и заканчивая популярными фреймворками, такими, как TensorFlow и PyTorch. 
Источник: WCCFTech Сложность BR100 внушает уважение: новый чип состоит из 77 млрд транзисторов, скомпонованных воедино с использованием 7-нм техпроцесса и технологии TSMC 2.5D CoWoS. Площадь чипа составляет 1074 мм2, правда, не очень понятно, идёт ли речь исключительно о кристалле, т.н. «вычислительном тайле», или о сборке в целом, поскольку в состав BR100 входит 64 Гбайт памяти HBM2e. 
Источник: WCCFTech Среди особенностей можно отметить наличие быстрого кеша объёмом 300 Мбайт (256 Мбайт L2) — для сравнения, у NVIDIA A100 он составляет всего 40 Мбайт, и даже у новейшего H100 он увеличен лишь до 50 Мбайт. Что касается ПСП, то она составляет 1,64 Тбайт/с. 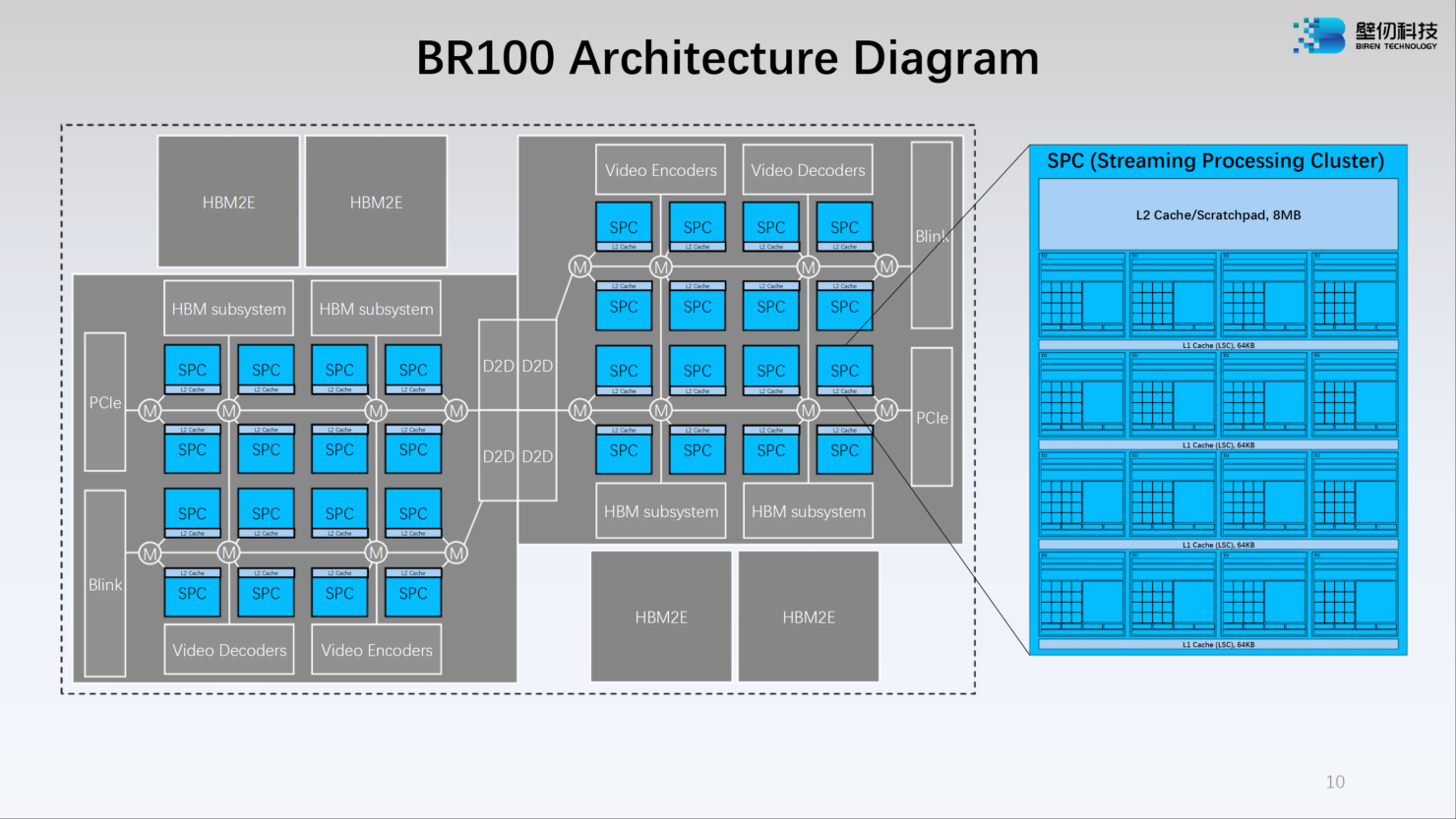
Источник: WCCFTech Модульная компоновка BR100 включает в себя два вычислительных тайла и четыре сборки HBM2e. Между собой кристаллы соединены интерконнектом с пропускной способностью 896 Гбайт/с, а для дальнейшего масштабирования в составе нового ускорителя предусмотрен фирменный интерконнект BLink (8 линий) с производительностью 2,3 Тбайт/с. 
Источник: WCCFTech Каждый из двух кристаллов несёт в себе по 16 потоковых вычислительных кластеров (SPC), а каждый такой кластер, в свою очередь, содержит 16 исполнительных блоков (EU). Каждый блок EU содержит 16 потоковых ядер V-Core и одно тензорное ядро T-Core, так что всего в составе BR100 имеется 8192 классических ядра и 512 тензорных. Каждый SPC имеет свой кеш L2 объёмом 8 Мбайт, суммарно 256 Мбайт на всю сборку BR100. 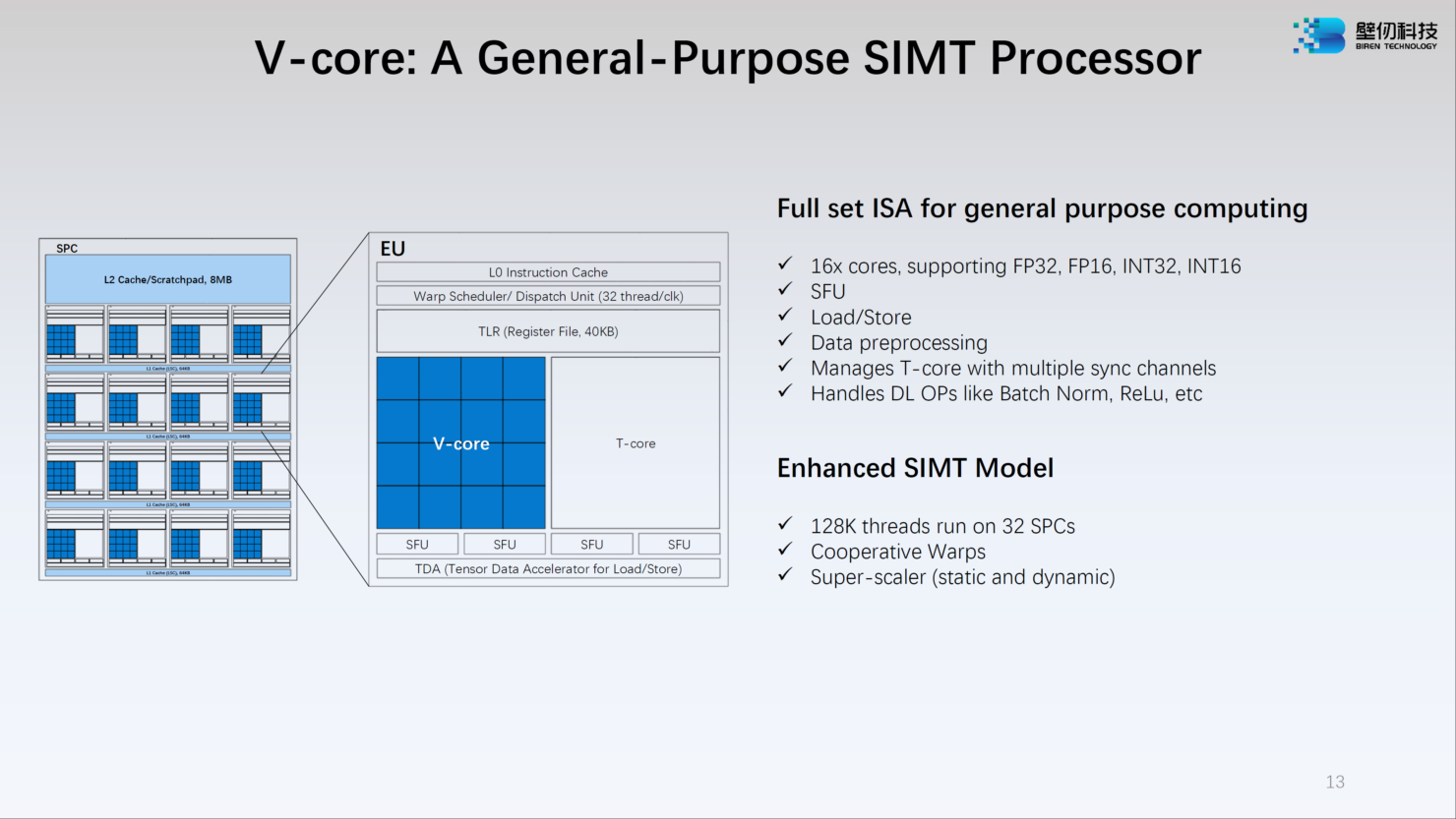
Источник: WCCFTech Ядро V-Core имеет архитектуру SIMT (Single Instructions, Multiple Thread) и поддерживает вычисления в форматах INT16/32, FP16 и FP32. Тензорные ядра T-Core предназначены для выполнения операций типа MMA, свёртки и прочих, характерных для современных задач машинного обучения. Предельное количество потоков у BR100 в суперскалярном режиме — 128 тысяч. 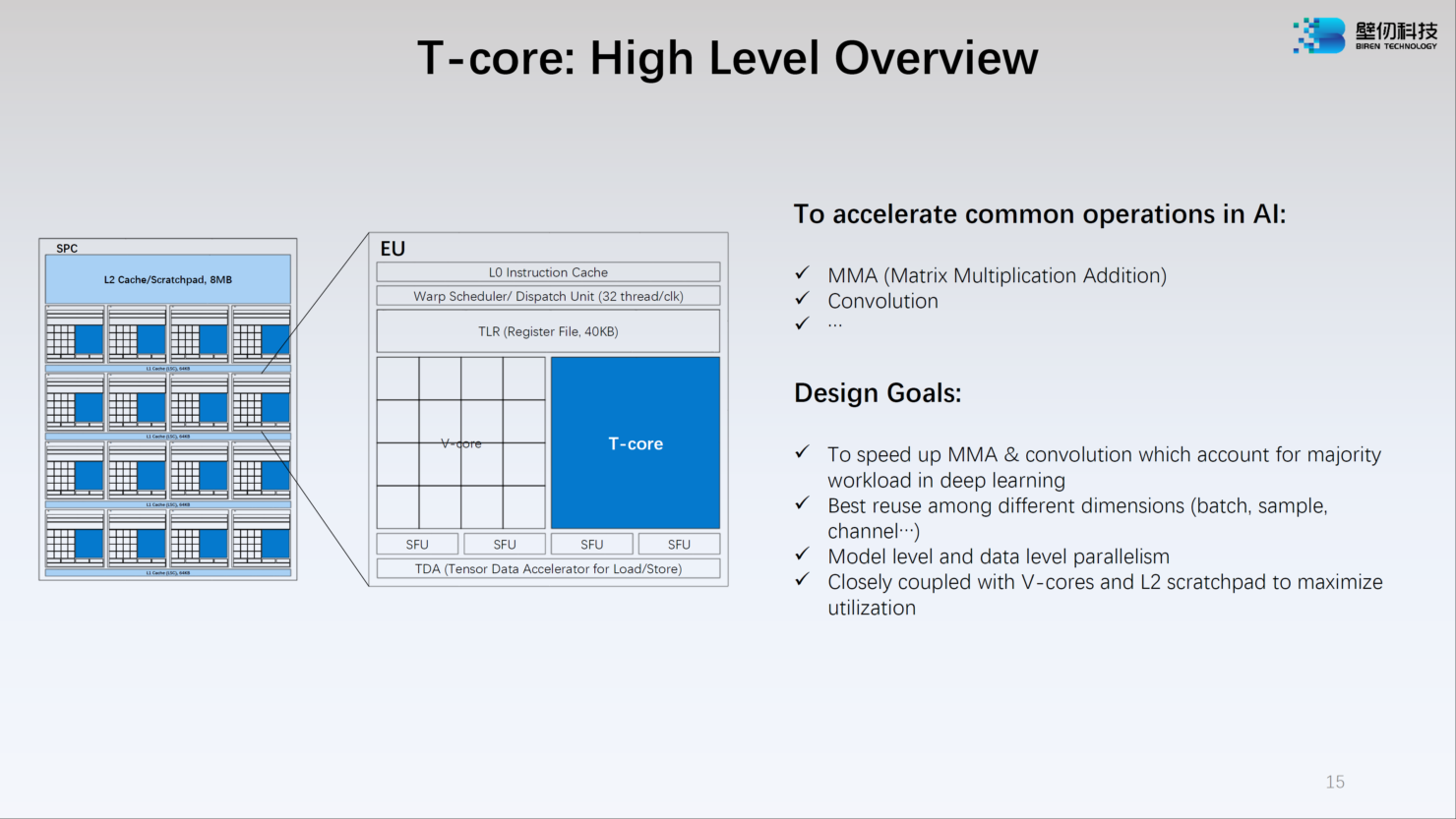
Источник: WCCFTech Компания-разработчик приводит некоторые цифры производительности для BR100: это 256 Тфлопс в режиме FP32, вдвое больше в режиме TF32+, 1024 Тфлопс в формате BF16 и целых 2048 Топс в режиме INT8. Это серьёзная заявка: с такими показателями BR100 должен опережать NVIDIA A100. Заявлено превосходство от 2,5х до 2,8х в зависимости от задачи и сценария. 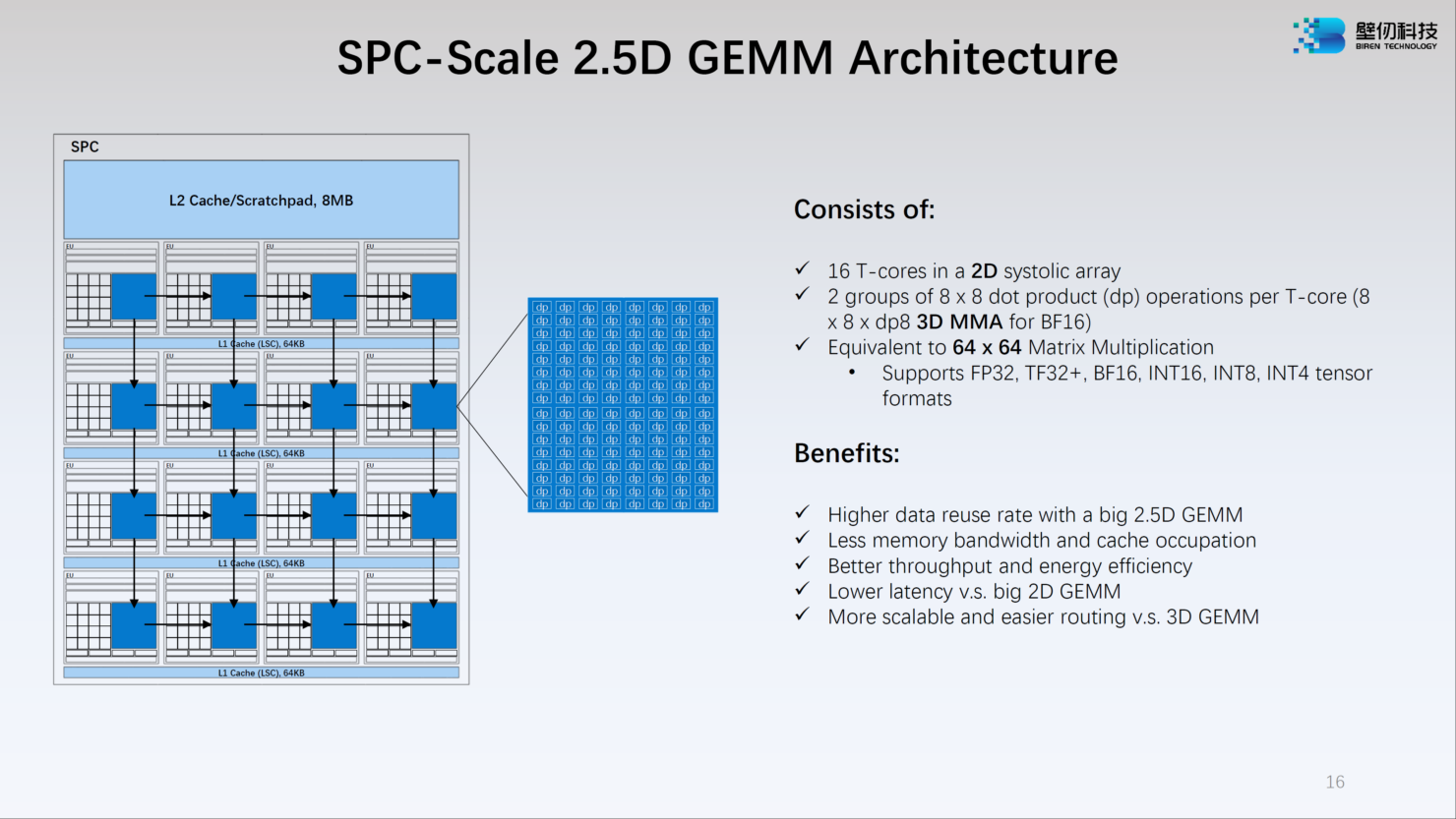
Источник: WCCFTech Любопытно, что BR100 несильно уступает NVIDIA H100 по количеству транзисторов (77 против 80 млрд), но, естественно, использование более грубого 7-нм техпроцесса против N4 у последней разработки NVIDIA означает и большее тепловыделение. Этот параметр у BR100 составляет 550 Вт в то время, как PCIe-вариант H100 укладывается в стандартные 350 Вт. 
Источник: WCCFTech Это не единственная новинка: в арсенале Birentech заявлен и менее мощный чип BR104. Он вдвое медленнее старшей модели по всем показателям и несёт 32 Гбайт памяти против 64, но в отличие от BR100, использует монолитный, а не чиплетный дизайн. На его основе будут выпущены ускорители в формате PCIe с TDP в районе 300 Вт, тогда как старшая версия будет доступна только в виде OAM-модуля.
09.08.2022 [18:09], Игорь Осколков
Китайская компания Biren представила ИИ-ускоритель BR100, который обгоняет по производительности NVIDIA A100Шанхайская компания Biren Technology, основанная в 2019 году и уже получившая более $280 млн инвестиций, официально представила серию ускорителей BR100, которые способные потягаться с актуальными решениями от западных IT-гигантов. Утверждается, что это первое изделие подобного класса, созданное в Поднебесной. Компания уже подписала соглашение о сотрудничестве с ведущим производителем серверов Inspur. Новинка содержит 77 млрд транзисторов, использует чиплетную компоновку, изготавливается по 7-нм техпроцессу на TSMC и имеет 2.5D-упаковку CoWoS. Для сравнения — грядущие NVIDIA H100 имеют такую же упаковку, но включают 80 млрд транзисторов и изготавливаются по более современному техпроцессу TSMC N4. При этом BR100 примерно вдвое производительнее 7-нм NVIDIA A100 и примерно вдвое же медленнее H100. Впрочем, Biren приводит только данные о вычислениях пониженной точности, да и в целом говорит о том, что новинка предназначена в первую очередь для ИИ-нагрузок. 
Изображения: Biren В серию входят два решения: BR100 и BR104. Оба варианта оснащаются интерфейсом PCIe 5.0 x16 с поддержкой CXL. Первый вариант имеет OAM-исполнение с TDP на уровне 550 Вт. Он позволяет объединить до восьми ускорителей на UBB-плате, связав их между собой фирменным интерконнектом BLink (512 Гбайт/с) по схеме каждый-с-каждым. BR100 полагается 300 Мбайт кеш-памяти и 64 Гбайт HBM2e (4096 бит, 1,64 Тбайт/c). 
BR100 Также он способен одновременно кодировать до 64 потоков FullHD@30 HEVC/H.264, а декодировать — до 512. Кроме того, доступно создание до 8 аппаратно изолированных инстансов Secure Virtual Instance (SVI) по аналогии с NVIDIA MIG. Заявленная производительность составляет 256 Тфлопс для FP32-вычислений, 512 Тфлопс для TF32+ (по-видимому, подразумевается некая совместимость с фирменным форматом NVIDIA TF32), 1024 Тфлопс для BF16 и, наконец, 2048 Топс для INT8. 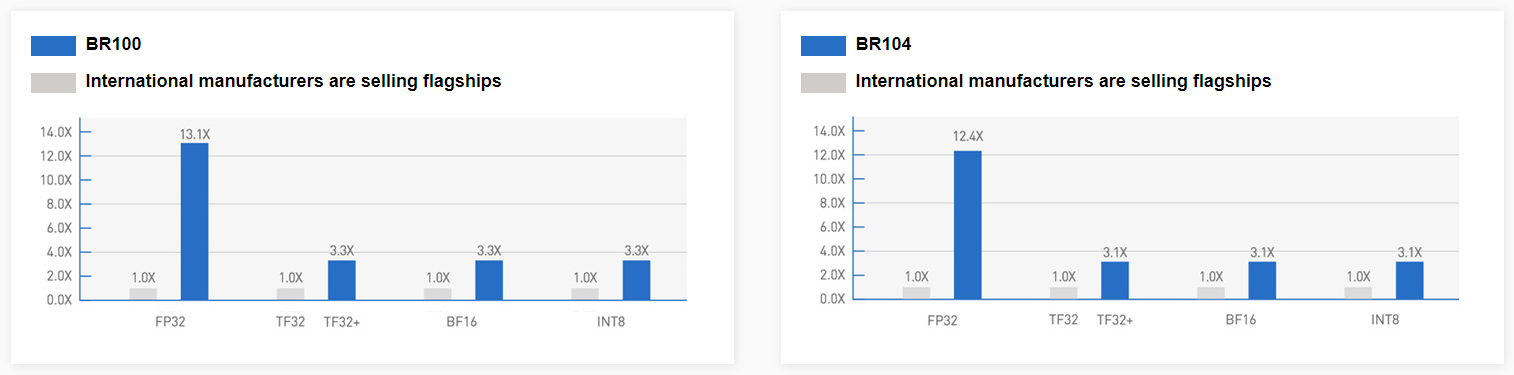 
BR104 BR104 представляет более традиционную FHFL-карту с TDP на уровне 300 Вт. По производительности она ровно вдвое медленнее старшей версии BR100, способна обрабатывать вдвое меньшее количество видеопотоков и предлагает только до 4 SVI-инстансов. BR104 имеет 150 Мбайт кеш-памяти, 32 Гбайт HBM2e (2048 бит, 819 Гбайт/c) и три 192-Гбайт/с интерфейса BLink. Для работы с ускорителями компания предлагает собственную программную платформу BIRENSUPA, совместимую с популярными фреймворками PyTorch, TensorFlow и PaddlePaddle. |
|

